Korea Bioinformation Center
국내 생명연구자원정보의 총괄관리와 생명정보 분야의 전문연구를 위한 범부처 국가센터

KOBIC 공지
- 2025-10-16
- 2025-10-15
- 2025-09-22
최신 연구 등록 정보
- Project IDKAP241913
- NTIS 과제번호2460002371
공개 분석 파이프라인
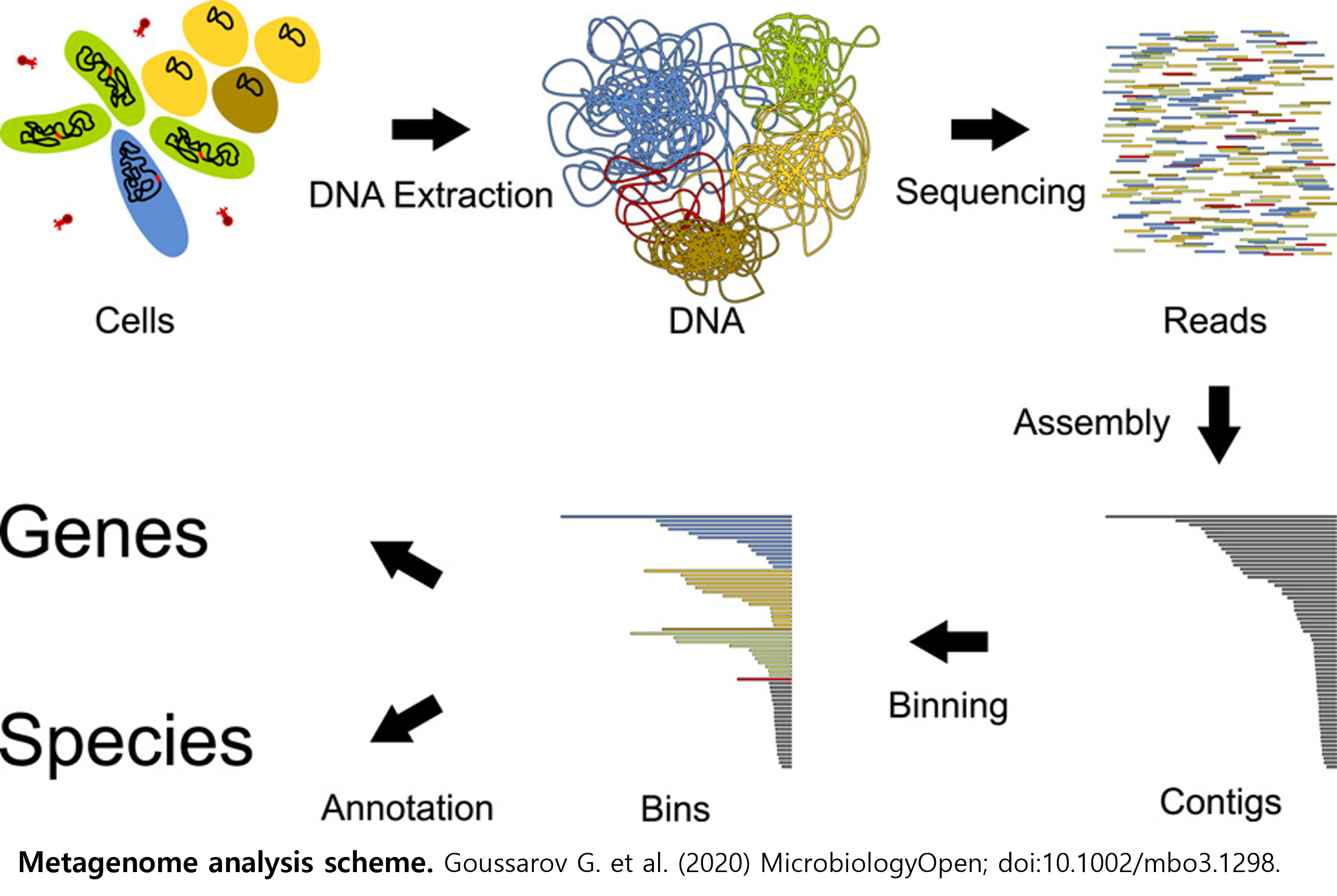
.png)

바이오익스프레스 서비스는 동적 컨테이너 기반 자동화된 워크플로우 분석 플랫폼과 고속 데이터 전송 서비스를 통해 과학 분야의 빅데이터 분석을 가능하게 하는 국내 유일의 클라우드 기반 통합 데이터 분석 서비스입니다.
다운로드
환경에 맞는 OS용 워크벤치 및 고속전송 서비스를다운로드 해주세요.
- CLOSHA : 클라우드 기반 대용량 유전체 분석 플랫폼 - GBOX : 대용량 데이터 고속 전송 서비스 - SFTP : 보안 (SSH) 프로토콜 기반 데이터 전송 서비스
6,790명
누적 사용자96,589건
누적 건수바이오 연구 데이터란 생명과학 분야의 국가 R&D 사업을 통해 생산된 모든 종류의 데이터를 의미하며, 이러한 데이터를 활용한 혁신 연구 방식이 각광받으면서 R&D 혁신을 견인하는 핵심요소로 부각되고 있습니다. 이를 위하여 부처·사업·연구자별 흩어져 있는 데이터를 통합 수집·제공하는 국가바이오데이터스테이션을 구축하여 데이터 기반 바이오 연구 환경을 조성하려 합니다.
데이터별 등록 현황
-
2,503건
바이오프로젝트 -
164,743건
바이오샘플 -
2,433,487건
등록된 데이터
바이오 프로젝트 등록 현황
등록 누적 건수(건)
정밀의료의 근간이 되는 바이오 빅데이터는 사후적 치료 중심에서 개인 맞춤형 치료·예방의료로 전환됨에 따라 중요도가 커지고 있습니다. 특히 선점 효과가 큰 바이오 산업의 경우 선제적 투자가 필요하며, 주요국들은 대규모 바이오 빅데이터를 구축하고 있습니다. 이에 따라 국가적으로 미래 의료 선도를 위한 국가 바이오 빅데이터를 구축하기 위해 본 사업이 시행되었습니다. 정밀의료 시대의 중심인 '바이오 빅데이터'를 국가차원에서 수집-저장-활용 할 수 있는 기반을 조성하고, 신산업 촉진 및 건강한 삶의 증진에 기여하고자 합니다.
16개 희귀질환 협력기관을 지정 운영하여 희귀질환자 모집 후 임상정보 수집
수집된 희귀질환자의 검체를 자원 제작 기관으로 운송 후 유전체 데이터 생산ㆍ분석
수집된 임상정보 및 유전체 데이터는 3개의 기관에서 컨소시엄을 구성해 공유
분석한 데이터는 희귀질환자 상담 및 진료 ㆍ연구 활동 등에 활용
데이터 현황
감염병 연구정보포털(Infectious Disease Data Portal)은 전 세계 감염병 바이러스의 연구데이터를 통합 제공하는 포털 서비스 입니다. 빠르게 변화하는 상황에서 감염병을 이해하고 치료법과 백신을 개발하기 위해 데이터와 결과를 조화롭게 공유하기 위해 KOBIC은 전세계 감염병의 연구정보데이터를 통합하여 제공하고 있습니다.
시퀀스 대시보드
감염병 개요, 입자 및 유전체 구조, 생활사, 역학, 변이 등 바이러스에 대한 통합 정보를 제공
전세계에서 수집한 염기서열 및 단백질 서열, 단백질 구조를 품질분석하여 제공
바이러스 데이터의 발병 시기, 지역, 변이 등 다양한 통계 서비스
간단한 웹 기반의 감염병 표준 염기서열 BLAST 서비스
교육지원
- 042-879-8582
- bkbaik@kribb.re.kr
[종료] 제 52회 차세대 생명정보학 교육 워크샵 - Oxford Nanopore Technologies : Introduction to applications and analysis workflow
- 일시25. 08. 28(목) 13:00 ~ 25. 08. 28(목) 17:00
- 장소한국생명공학연구원 KOBIC동 3층 교육실
[종료]제 51회 차세대 생명정보학 교육 워크샵 - 고해상도 공간 전사체 분석 워크샵
- 일시25. 07. 17(목) 12:30 ~ 25. 07. 17(목) 17:30
- 장소한국생명공학연구원 KOBIC동 3층 교육실
교육지원 누적 실적(건)
협력기관






